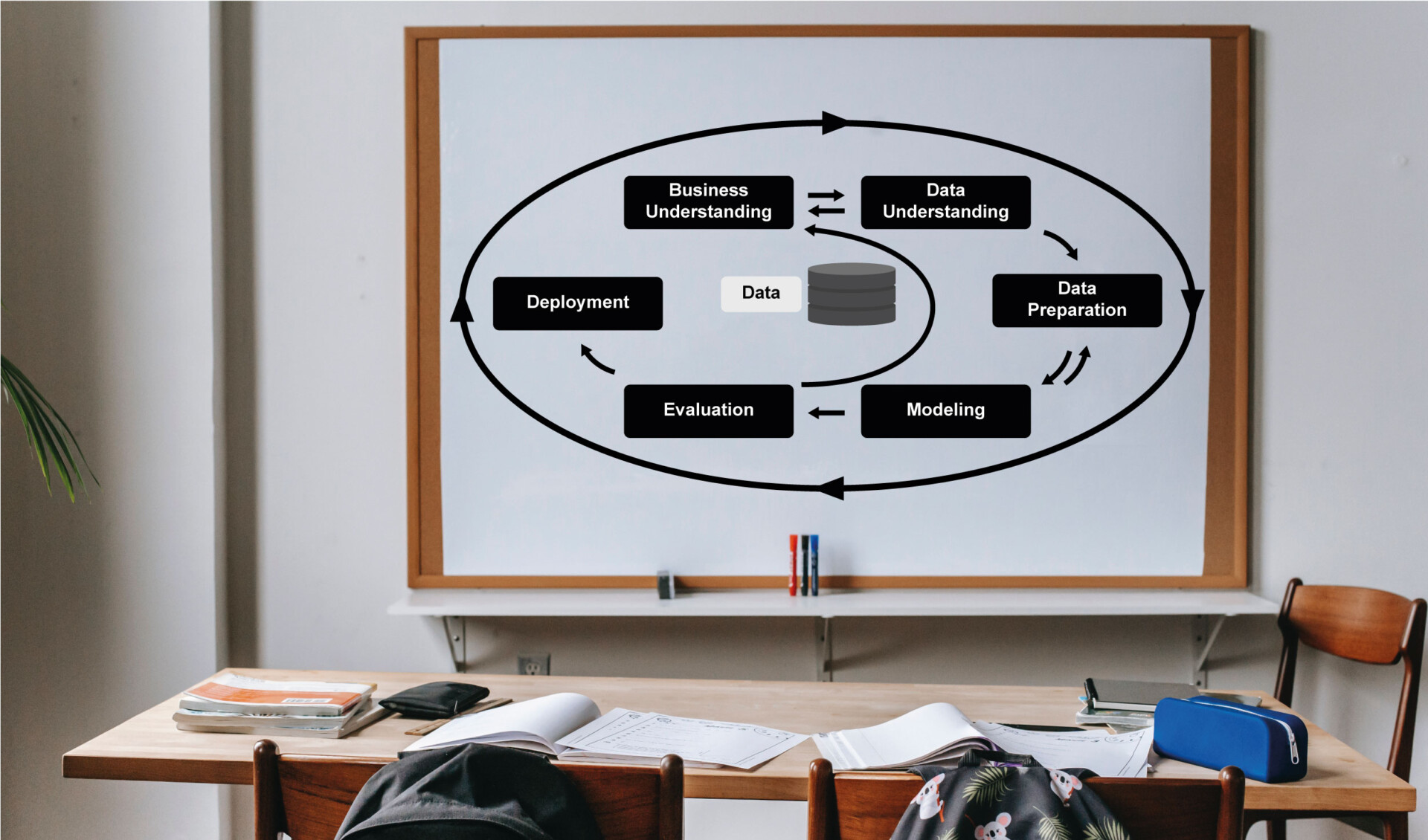
In Zeiten der Digitalisierung sind Informationen die Währung, mit der wir alle täglich und überall bezahlen. Die gesammelten Daten werden verarbeitet und sortiert, sodass auf Grundlage der Erkenntnisse Entscheidungen getroffen werden können. Die Verarbeitung wird dabei von Algorithmen übernommen. Welche verschiedenen Algorithmen es gibt und wie diese funktionieren erfährst du in der Veranstaltung Machine Learning und Data Mining des Moduls Data Analytics.
Machine Learning wird ein immer größerer Bestandteil verschiedenster Technologien und wird beispielsweise im Online-Handel für Produktempfehlungen oder bei der Steuerung von autonom fahrenden Autos eingesetzt. Durch die steigende Wichtigkeit wird dieses Wissen deshalb auch durch Prof. Volker Sänger in der hier vorgestellten Lehrveranstaltung Data Mining vermittelt, welche ein Teil des Moduls Data Analytics ist.
Facts
· Pflichtfach innerhalb des Moduls Data Analytics
· jedes Wintersemester am Campus Offenburg
· für alle Masterstudierende aus Dialogmarketing und E-Commerce
· als Teil eines Wahlpflichtmoduls auch für Studierende aus Medien und Kommunikation
· bestehend aus Vorlesung, Labor und Übungsstunden
· Prüfungsform: 30-minütige schriftliche Klausur
· zwei Semesterwochenstunden
· drei ECTS
Für eine genauere Übersicht der einzelnen Bestandteile des übergeordneten Moduls Data Analytics ist hier auch noch eine kurze grafische Einsicht von Aufbau, Stunden- und Creditverteilung der unterschiedlichen Modulbestandteile abgebildet.

Teil 1: die Vorlesung
Die Vorlesung des Fachs wird von Prof. Sänger selbst gehalten und findet einmal in der Woche statt. In den Vorlesungen werden mit vereinfachten zweidimensionalen Beispielen die verschiedenen Machine Learning Algorithmen erklärt. Diese werden mithilfe von vorhandenen Daten trainiert, um Modelle zu erstellen und so für zukünftige Daten Voraussagen treffen zu können. Das Zitat von Arthur L. Samuel fasst Machine Learning dabei sehr gut und einfach zusammen:
[Machine learning is the] field of study that gives computers the ability to learn without being explicitly programmed.
Arthur L. Samuel (1959)

Während der Vorlesung werden die Funktionsweise, die Anwendung sowie die Vor- und Nachteile der verschiedenen überwachten und unüberwachten Lernalgorithmen vorgestellt. Dabei wird die Anwendung nicht nur theoretisch behandelt, sondern auch anhand von greifbaren Beispielaufgaben, wie der passenden Weiterleitung von Mails an Fachmitarbeiter*innen oder der Einstufung der Kreditwürdigkeit von Bankkund*innen erklärt. Das praktische Anwenden der Algorithmen wird zusätzlich in den Übungen vertieft.
Teil 2: die Übungen
Die zur Vorlesung zusätzlich stattfindenden Übungen werden von Frau Gisela Hillenbrand geleitet und laufen begleitend zum Vorlesungsstoff ab. Über das Semester verteilt finden drei 90-minütige Veranstaltungen statt in denen jeweils Aufgaben zum vorangegangen Vorlesungsstoff bearbeitet werden.
Die Aufgaben werden dabei eine Woche vor der stattfindenden Übung in Moodle bereitgestellt und in Einzelarbeit von den Studierenden gelöst. Die Lösung jedes einzelnen wird dann über die Abgabefunktion der E-Learning-Plattform eingereicht und von Frau Hillenbrand korrigiert und bewertet. Die korrigierte Lösung wird zur Einsicht hochgeladen, sodass die eigenen Fehler selbst begriffen werden können. In der Übungsstunde selbst werden die Aufgaben dann noch einmal zusammen mit der Dozentin besprochen, um eventuelle Fehler zu beheben oder Verbesserungsvorschläge zu erarbeiten. Die Übungen sind dabei sehr hilfreich für die Klausurvorbereitung, da so der optimale Lösungsweg direkt diskutiert und dargestellt sowie Fragen zu den Aufgaben direkt beantwortet werden können.
Teil 3: das Labor
In den Übungen des Moduls werden die grundsätzliche Arbeitsweise und die händische Anwendung der Algorithmen vermittelt, jedoch geht die Vorlesung, mit der Einführung in das Programm KNIME, noch einen Schritt weiter.

KNIME ist eine kostenlose Software für die Datenanalyse, die mithilfe von Drag & Drop Bausteinen die Abläufe der verschiedenen Algorithmen sehr simpel und verständlich darstellt. Da die Lösung einer kompletten KNIME-Aufgabenstellung innerhalb der Vorlesung jedoch zu viel Zeit in Anspruch nehmen würde, wird den Studierenden mit dem Labor die Möglichkeit gegeben, in Eigenarbeit mit einer ausführlichen Anleitung, das Programm selbst kennen zu lernen. Vorteilhaft ist dabei, dass das Programm sehr viel größere und komplexere Datensätze in kürzester Zeit verarbeiten kann und so einen wirklichen Bezug zur Datenanalyse im Alltag schafft.
Teil 4: die Klausur
Die Prüfungsleistung des übergeordneten Moduls Data Analytics setzt sich aus einer Modulklausur der beiden Vorlesungen und einem Referat des Seminars zusammen. In der 60-minütigen Modulklausur müssen die Studierenden innerhalb von 30 Minuten circa vier Aufgaben der Vorlesung Data Mining lösen. Die Aufgaben behandeln dabei die praktische Durchführung von verschiedenen Lernalgorithmen, die anhand von leicht verständlichen und kleinen Datensätzen bearbeitet werden müssen. In kleinen Teilaufgaben wird zusätzlich das theoretische Wissen abgefragt. Als Hilfsmittel ist ein nicht programmierfähiger Taschenrechner erlaubt.
Damit du dich für die Klausur gut vorbereiten kannst, hier auch noch ein paar Tipps:
- Präge dir den in der Vorlesung gezeigten Lösungsweg ein, so fällt dir das Lösen der Aufgaben in den Übungen und der Klausur leichter.
- Die Aufgaben in den Übungsstunden sind ungefähr auf dem Leistungsniveau der Klausur, löse sie vollständig und mit Sorgfalt, so bereitest du dich schon vor der Prüfungsphase vor.
- Nimm dir ausreichend Zeit zum Üben und beginne rechtzeitig mit dem praktischen Üben. Falls du mehr Struktur in deine Vorbereitung bringen willst, kannst du dir auch mit dieser Anleitung in nur vier Schritten deinen eigenen Lernplan erstellen.
- Die früheren Klausuren sind im Moodle-Kurs verfügbar. Du kannst die Aufgaben unter „realen Bedingungen“ (keine zusätzlichen Aufschriebe, 30 Minuten Zeit) lösen, so trainierst du gezielt für die Klausur.
- Da 30 Minuten sehr schnell vorbei sein können, solltest du in der Klausur zunächst mit den Aufgaben beginnen, die du gut beherrschst und auch während des Lernens sicher und schnell lösen konntest.
- Solltest du Fragen haben kannst du dich in der letzten Übung oder der Klausurvorbereitung an Prof. Sänger oder Frau Hillenbrand wenden.
Fazit
Der Kurs hat mir anhand von leicht vorstellbaren und einfachen Beispielen gezeigt, wie die Datenanalyse im Hintergrund funktioniert. Ich hatte davor zwar eine grobe Vorstellung was Machine Learning ist, aber durch diesen Kurs kenne ich nun auch die teils komplexen Vorgänge dahinter und kann sie auch anderen Personen erklären oder mit ihnen darüber diskutieren. Vor allem in Verbindung mit den statistischen Einblicken des dazugehörigen Teilfachs von Prof. Drechsler und dem Seminar Trends im Datenmanagement ist das Gesamtmodul für mich ein vollständiger Einblick in das Gebiet Data Analytics.
Welche Wahlpflicht- und Pflichtfächer dich sonst noch im Masterstudiengang Dialogmarketing und E-Commerce erwarten, kannst du auch in folgenden anderen Beiträgen erfahren:



Quellen
Analytic-Programm KNIME: https://www.knime.com/knime-analytics-platform
Data Mining: https://www.bigdata-insider.de/was-ist-data-mining-a-593421/
Eigene Erfahrungen und Aufschriebe aus der Data Mining und Analytics Vorlesung des Wintersemester 20/21
Machine Learning: https://imla.gitlab.io/ml-buch/ml2-buch/
Überwachtes und unüberwachtes Lernen: https://data-science-blog.com/blog/2017/07/02/uberwachtes-vs-unuberwachtes-maschinelles-lernen/
Zitat: Samuel, Arthur L. “Some Studies in Machine Learning Using the Game of Checkers,” IBM Journal of Research and Development 44:1.2 (1959): 210–229.
Bildquellen
Titelbild: Eigene Bearbeitung mit eigens erstellter Grafik des CRISP-Modells, Hintergrundbild von Katerina Holmes (https://www.pexels.com/de-de/foto/klassenzimmer-mit-whiteboard-und-schreibtisch-mit-schreibwaren-5905441/)
Bild Labor: Screenshot aus dem kostenfreien Programm KNIME